1.K-近邻(KNN)算法
简述:给定一个训练样例集合,找出k个与需分类的样本最相似的样例,统计这k个样例中的出现次数最多的分类,即可将输入例子归到这一类中。
KNN算法用于分类时,每个训练数据都有明确的label,也可以明确的判断出新数据的label,KNN用于回归时也会根据邻居的值预测出一个明确的值,因此KNN属于监督学习。
步骤:
-
选择一种距离计算方式, 通过数据所有的特征计算新数据与已知类别数据集中的数据点的距离
-
按照距离递增次序进行排序,选取与当前距离最小的k个点
-
对于离散分类,返回k个点出现频率最多的类别作预测分类;对于回归则返回k个点的加权值作为预测值
缺陷:
- k临近算法是基于实例的学习,使用算法时必须有接近实际数据的训练集。
- 由于需要对数据集中的每个数据进行距离计算,因此非常耗费时间。
2.决策树
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不详关特征数据。
- 缺点:可能会产生过度匹配问题。
- 适用数据类型:数值型和标称型。

- 通过计算殇的变化来找到最佳切分的特征
- 找到最佳切分的特征之后,通过其可能出现的值来创建子树直至所有的元素都属于同一类
小结
-
“过度匹配overfitting”:匹配的项太多了,为了解决这一问题,可以对树进行剪裁,去掉一些不必要的叶子节点,如果叶子节点只能增加一点点的信息,则可以删除该节点,让后并入其他节点里面。
- 本章采用的划分方法叫做ID3。首先测量数据集合的熵(不确定度),找出最优的划分点,直至数据集中的子集全部属于某个分类,如果特征已经用完了就采用最大数量投票的方法(少数服从多数,即子集里面出现最多次数的分类)。
- ID3缺点是无法处理数值型数据。尽管可以用量化的方法将数值型数据转换为标称型数据,但是ID3的存在太多的特征划分的话也会出现其他问题。
- 树的存储不需要用其他数据结构,直接用python的字典存储。然后用matplotlib的注解功能进行树的可视化。
- 另外一些流行的划分方法:C4.5 or CART
- 前面两章都是介绍了结果确定的分类算法,即测试数据一定能分类到某一类别上。接下来的一章不给出确定分类,只给出归属于哪个类的概率。
3.朴素贝叶斯
 贝叶斯公式:
贝叶斯公式:
P(Ci|X) = \frac{P(C_iX)}{P(X)} = \frac{P(X|C_i)P(C_i)}{P(X)}
- 贝叶斯假设变量X间是条件独立的(假设有n个特征),故:
P(C_i|X) = \frac{P(Cix_1)P(Cix_2)...P(Cix_n)}{P(X)} - 两种实现方式:一种是基于贝努利模型实现,另一种是基于多项式模型实现。前一种不考虑次数,之考虑出不出现。后一冲考虑词在文档中的出现次数。
- 词集模型:只统计出现与否
- 词袋模型:统计出现的次数
小结
- 贝叶斯准则为我们提供了一个利用已知值预测未知概率的途径
- 独立性假设:假设特征之间都是相互独立的
- 下溢出:利用对数即可解决
4.logistic回归
- 利用logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归”一词源于最佳拟合,表示要找到最佳你和参数集。
- 训练分类器的做法就是寻找最佳拟合参数,使用的是最优化算法。
- logistic回归的过程:

话外(结构化数据)
-
结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)
- 非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等
- Sigmoid函数用来代替单位阶跃函数(瞬间跳跃有时候很难处理)
\sigma(z) = \frac{1}{1+e^{-z}} - logistic回归做法:在每个特征上乘上一个回归系数,然后把所偶的结果值相加,将这个综合代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。所以,Logistic回归也可以被看作成一种概率估计。
问题:最佳的回归系数是多少?如何确定大小?
- 梯度上升法:找最大值:
\vec{w}:= \vec{w} + \alpha\nabla_wf(\vec{w}) - 梯度下降法:找最小值
\vec{w}:= \vec{w} - \alpha\nabla_wf(\vec{w})PS:f()是损失函数
- 梯度下降和上升在一定程度上是等价的,可以对损失函数进行取反求得。
- 经过推理求导后可得:
\frac{d}{dw}f(w) = X^T(Xw - Y)ps:w是列[[],[],[]]
为减少数据庞大时的计算量:随机梯度上升
- 随机梯度上升算法:一次仅用一个样本点来更新回归系数。(属于在线学习算法)
- 与“在线学习”相对应的是一次处理所有数据的“批处理”
算法代码:

小结
- 目的:Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法来完成。
- 在最优化算法中,最常用的就是梯度下降算法—,为了减少计算量,改进算法为随机梯度下降算法。
- 随机下降算法是在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批处理运算。
5.支持向量机SVM

- 分隔超平面(separating hyperplane):将数据集分割开来。如果数据是1024维的,那么就需要一个1023维的某某对象来对数据进行分隔。
- 支持向量(support vector):离分隔超平面中最近的那些点。我们希望确保这些点离分隔面的距离尽可能远。
- 几何间隔(margin):支持向量到分隔面的距离
- 核函数:将数据转化为向量机容易理解的形式

- 其实就是求几何间距最大:
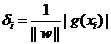
-
一般来说为了求最大的几何间距,我们会将间距 g() =1(这是指把所有样本点中间隔最小的那一点的间隔定为1),然后求最小 w 即可,那 w == 0得时候不久可以了吗?这样的话间距就会无穷大,所有的点都会落到灰色不可分地带里。。。因此我们有限制条件,那就是所有点的间距要大于1 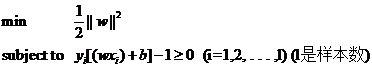
-
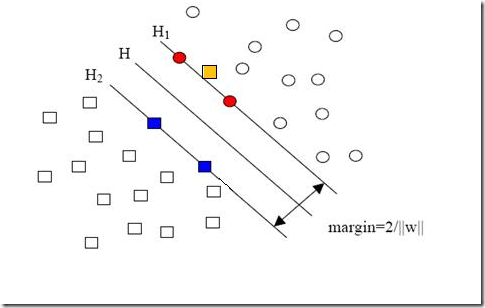
你肯定能看出来,一旦求出了w(也就求出了b),那么中间的直线H就知道了(因为它就是wx+b=0嘛,哈哈),那么H1和H2也就知道了(因为三者是平行的,而且相隔的距离还是 w 决定的)。那么w是谁决定的?显然是你给的样本决定的,一旦你在空间中给出了那些个样本点,三条直线的位置实际上就唯一确定了(因为我们求的是最优的那三条,当然是唯一的),我们解优化问题的过程也只不过是把这个确定了的东西算出来而已。
样本确定了w,用数学的语言描述,就是w可以表示为样本的某种组合:
w=α1x1+α2x2+…+αnxn
- 因为要顾及到正负类的划分,因此标签页必须考虑进去。你回头看看图中正样本和负样本的位置,想像一下,我不动所有点的位置,而只是把其中一个正样本点定为负样本点(也就是把一个点的形状从圆形变为方形),结果怎么样?三条直线都必须移动(因为对这三条直线的要求是必须把方形和圆形的点正确分开)!这说明w不仅跟样本点的位置有关,还跟样本的类别有关(也就是和样本的“标签”有关):
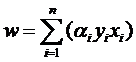
- 综合g(x), 有:
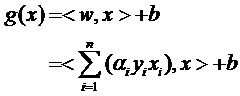
- 其中ai和yi都不是向量,xi是样本向量(很多维):

- 发现了什么?w不见啦!从求w变成了求α。
- 核函数:高维可能更容易线性划分,但是找映射太麻烦了,我们关注的其实只是内积,最后只是一个总和值….因此能否存在K(w, x) = <w
, x> PS:x,x是高维的意思 - 有!这种函数就叫做核函数(kernel):
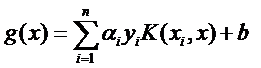
少数点线性不可分怎么办?近似线性可分咯
- 向上图那样,怎么映射到高维也线性不可分。那个数据点可能是错误的,我们人一般会忽略它,但是算法没那么智能,因此引入“松弛变量”
- 约束条件此时变为:
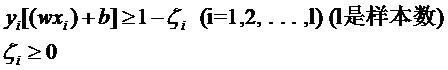
- 整个优化问题变成:
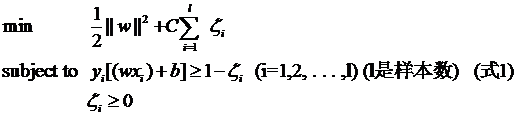
- 因为松弛变量是非负的,因此最终的结果是要求间隔可以比1小。但是当某些点出现这种间隔比1小的情况时(这些点也叫离群点),意味着我们放弃了对这些点的精确分类,而这对我们的分类器来说是种损失。但是放弃这些点也带来了好处,那就是使分类面不必向这些点的方向移动,因而可以得到更大的几何间隔(在低维空间看来,分类边界也更平滑)。显然我们必须权衡这种损失和好处。好处很明显,我们得到的分类间隔越大,好处就越多。
- 惩罚因子:你有多重视“离群点”,越大,这个点就越不可以丢
- 注意:只有“离群点”松弛变量才会有值
- 松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
- 最后,一旦αi得到,其他变量w,b,ξ和π都可以由之前的KKT条件计算得到。
补充:多分类问题
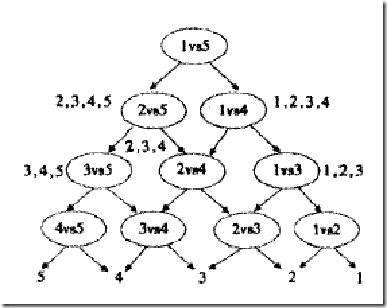
- 众所周知的是,SVM是一个二类的分类器。处理多分类问题有下面三种方法:
- 假如此时有五个类
- 一对多。就是训练5个分类器,第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,如此类推
- 一对一。C25把所有两个类别都组合起来。
- DAG模式:
小结
- 引入核函数和松弛变量都是为了将线性不可分问题转化为线性可分。
- 那同样的目标为什么要引用两种不一样的方法呢?因为有时候引入了核函数还是会不可分,但是比不引入核函数更接近与线性可分的状态,这时候忽略那些顽固的“离群点”可能就可以线性可分了。
- 惩罚因子C的另一应用:另外还有上次提到的“数据集偏斜”问题。比如负类少,正类多,就可以给负类设更大的C,说明这几个点更加重要。著名的Libsvm库就是选择用这种方法去做的。
6.利用adaboost元算法提高分类性能

- 机器学习也可以听取多个专家的意见而不是仅仅听命于一个人
- 有人认为adaboost是最好的监督学习算法
- 自举汇聚法(bagging):从原始数据集选择S次后得到S个新数据集的方法。待S个数据集合建立好后,训练得到S个分类器,进行投票选出最后的分类结果。
- 随机森林(random forest):数据集生成M个子集得到M个决策树,也是投票选取最多的类别作为最后的预测结果
- boosting:也是多个同类型的分类器,跟bagging不同的是,boosting专注于被已有分类器分错的数据来获得新的分类器(串行训练)。此外,与bagging所有分类器的权重都是平等这一点不一样,boost中的多个分类器的权重是不一样的。其每个分类器的权重代表着对应分类器上一轮的成功度。
Adaboost流程


训练
- 每个样本的权重最初是一样的,随着训练的分类器数量增多而发生改变,分错的样本的权重增加,分对的样本的权重减少
- 错误率的定义:
\epsilon = \frac{Number\ of\ samples\ which\ are\ not\ correctly\ classified}{Number\ of\ samples} - 每个分类器的权重alpha,用来更新样本的权重和与其他分类器一起用来加权求和得分类结果:
\alpha = \frac{1}{2}ln(\frac{1-\epsilon}{\epsilon}) - 如果某个样本被正确分类,其权重变为(除SUM(D)是归一化的过程):
D^{t+1}_i = \frac{D^{t}_ie^{-\alpha}}{SUM(D)} - 如果某个样本被错误分类,其权重变为:
D^{t+1}_i = \frac{D^{t}_ie^{\alpha}}{SUM(D)}
非均衡分类问题
- 比如说,预测马是否得疝气病,加入判断是的话可能需要对马进行安乐死而不是去治疗,因此在该例中两个类别的重要性不一样,分类的代价不一样
- 混淆矩阵:

- 正确率(Precision):预测为正例的样本中真正正例的比例
Prec = \frac{TP}{TP + FP} - 召回率(Recall):预测为正例的样本占总正例样本的比例
Reca = \frac{TP}{TP + FN} - 正确率和召回率是矛盾的,例如极端情况下全部例子判定为正例,那么召回率为100%但正确率很低
ROC曲线-分类器的性能比较方法
- 横轴是伪正例占所有样本中真正反例的比例(称为假阳率:FP/(TN + FP))
- 纵轴是真正例占所有样本中真正正例的比例(成为真阳率:TP/(TP + FN))
- ROC曲线最好的运动轨迹则是,先横移再下移,从(1,1)->(0,1)->(0,0),这样就是完全分类正确,错误率为0,因为ROC的画法是先按照预测强度排序,如果排序前面全是正确的,没有插入正例的话,那么曲线的运动轨迹是平移的,后面部分全是正例切分类正确,此时曲线就会下移至0
- AUS则是曲线的面积,最好为1
代价敏感的学习(cost-sensitive learning)
- 引入代价矩阵
- adaboost可以通过代价矩阵来调节样本权重,朴素贝叶斯可以选择最小期望代价的结果而不是最大概率,SVM在代价函数中选择不同的C
- 上述做法的实际上就是给代价更大的小类更大的权重,即在训练时,代价大的小类要有更小的错误率
处理非均衡的数据抽样问题
假设我们有50例正例,5000例反例
- 欠抽样:从5000例反例中随机删除4950例
- 过抽样:复制已有样例或者生成与样例相似的点。插值,但是可能导致过拟合。
- 结合:正例过抽样和反例欠抽样
接下来是回归问题-利用回归预测数值型数据
-
监督学习:有目标变量或预测目标的机器学习方法。回归则是目标变量为数值型数据
7.预测数值型数据:回归
- 目的:预测数值型的目标值。
线性回归
- 例子:HorsePower = 0.0015annualSalary - 0.99hourListening 其中这条公式就是回归方程,0.0015 0.99是回归系数,求回归系数的过程就叫做回归
- 回归一般可以被认为是线性回归(linear regression),就是输入×系数常量再加起来。但是也有非线性的回归
如何找到误差(平方误差)最小的w?
- 普通最小二乘法OLS(ordinary least squares)
solution:
-经过求导,得出权值叙述向量w可以由以下公式表示:
w = (X^TX)^{-1}X^Ty
- 计算两个序列的相关系数即可比较预测值和实际值的匹配程度
-
Numpy提供了corrcoef(yEstimate, yActual) 比较两组数据的相关性, 例子如下:

- 线性回归(最小均方误差的无差估计)可能出现欠拟合的现象
局部加权线性回归(LWLR)
- 给待预测的点附近的点一个权重
- 求解得出此时w的值为,其中W为权重向量:
w = (X^TWX)^{-1}X^TWy - 核函数,最常用的是高斯核(产生一个对角矩阵):
w(i,i) = exp(\frac{|x^{(i) - x}|}{-2k^2}) - k越小,用于训练回归模型的点也就少,如下:
- 当特征数大于样本数的时候,需要对数据进行“缩减”
- 岭回归,在矩阵X^TX 上加一个lambda*I (m行m列的单位矩阵矩阵)。
- 岭迹图:各个回归系数随lambda变化的趋势图,可以在曲线的‘喇叭口’位置找适当的lambda值
- lasso
- 逐步线性回归:能找出重要的特征.具体做法其实就是一个贪心的过程,每一维度的系数每次往最好的方面增加或者减少步长。个人感觉这样很容易陷入局部最优。
- 方差:模型之间的差异
- 偏差:模型预测值与数据之间的差异
- 我们需要找到方差和偏差的折中。
- 当应用缩减方法时(如逐步线性回归或者岭回归),模型也就增加了偏差(bias),与此同时减小了模型的方差。
9. 树回归

- 生活中许多问题都是非线性的,不可能用全局线性模型来建模
- 一种可行的办法就是将数据切割成多个易建模的数据,如果还是难以线性拟合的就继续切割划分,这种时候树结构和回归法就非常有用。

- CART(classification and regression ):二元切割法
- 混乱表示方式:总方差。也就是一个数据集的结果值得差距大不大来衡量。
- 切分方法:

- 剪枝(pruning):降低决策树的复杂度来皮面过拟合情况。
- 预剪枝:通过设定参数来提前裁剪树枝,例如设定一个节点中最小的数量集大小,或者最小的方差等等
- 后剪枝:在生成树之后合并树节点
模型树
- 模型树的特点是分段线性:模型由多个线性片段组成
- 与回归树相比,将节点的值换成线性模型
- 线性模型用简单的线性回归即可,注意如有必要在导入数据的时候第一维给增加常数项
- 找到最佳切分的计算误差方法:先对输入的数据进行拟合,求出预测的结果值,在与真实值做总方差计算。
模型树、回归树、一般的线性回归哪种模型比较好?
- 一种客观的解决方法是求相关系数R^2,利用numpy中的corrcoef(yPred, yActual)函数
- R^2越接近1效果越好
小结
- 非线性模型可以用树结构来建模,叶节点为常数则是回归树,为线性模型则是模型树
- CART算法可以构建二元树来处理连续或者离散数据的划分
- 一颗过拟合的树通常来讲会比较复杂,此时需要运用剪枝技术进行缩减。
- 剪枝可以分为预剪枝和后剪枝,预剪枝比较有效但需要用户自己调参。
总算是结束了监督学习,接下来的学习focus on 非监督学习
9. 利用K-means聚类算法对未标注数据进行数据分组
- 聚类(clustering):聚类是一种无监督学习,它将相似的对象归到同一个簇里。有点像全自动分类。
- 簇里面的数据越相似,说明效果就越好
- 簇识别(cluster identification):给出簇的含义,即这一部分数据代表着什么。
- K-均值缺点是容易陷入局部最佳
- 聚类的目标:保持簇数目不变的情况下提高簇的质量
- 评价聚类效果的其中一个指标是SSE,即是误差平方和。
- 如果聚类效果不好怎么改进?可将最大簇划分为两个簇,具体做法为将大簇的数据找出来再用kmeans算法划分,k此时为2.
为了保证簇总数不变,可以将合并另外两个簇,有两种量化的方法:
- 合并最近的质心(计算所有质心之间的距离)
- 合并两个使得SSE增幅最小的质心(在所有可能的两个簇上重复上述的处理过程,知道找到合并最佳的两个簇为止)
缺陷
- k与初始值有关
- K-Means算法需要用初始随机种子,不同的随机种子点会有得到完全不同的结果
10. 使用Aprior算法进行关联分析
-
关联分析 关联规则学习:从大规模数据集中寻找物品间的隐含关系。 - 穷搜是解决不了问题的,所以要利用Apriori算法
- 频繁项集:经常出现在一起的物品的集合
- 关联规则:暗示两种物品之间有很强的关系
如何定义频繁?
- 支持度(support):该项集占数据集的比例
- 可信度(confidence):针对关联规则来定义的
Apriori 算法原理
- 加入一个项集是非频繁的,那么它的超集也是非频繁的。
- Apriori具有两个参数,最小支持度(用来剔除项集),和数据集
- 一开始Apriori生成单个物品的项集,把小于最小支持度的项集去掉
- 在剩下的项集里面组成两个项的项集,把小于最小支持度的项集去掉
- 循环
- Aprior的关键是:连接和剪枝。
- 连接的意思是在组合成更大项集的时候拿前k-2项的值相等的list组成更大的list,例如{0,1},{1,2},{0,2} k = 3 生成更大的话就是 k - 3 = 1(就是第1项前面的所有项相同也就是0)第0项相同:{0,1} | {0,2}-> {0,1,2}就这样

-
一条规则P->H的可信度为support(P H) / support(P) - 可以看出如果一个关联规则的可信度不满足要求,那么改规则的子集也不会满足。这个意思是比如说买三件物品都不会买另外一件物品,那么买其中两个肯定不会买另外两件
- 对于每个频繁项集都产生所有的关联规则,测试是否满足最小支持度的要求
- 除了找出可信的关联规则以外,还可以找出只包含某些项的频繁项集。例如找出毒蘑菇里面出现的频繁特征,这样看到这些特征你就别吃这个野蘑菇了。
- Apriori其实就是一种节约计算资源求出频繁项集和关联关系的方法。
- 从单元素项集开始,通过找出满足最小支持度项集来组成更大的项集。
小结
- 适用于在大数量的项集中发现关联共现的项。
- 性能一般:在生成每个长度的候选频繁集的时候都要扫描整个数据集判断频繁集项是否是数据集项的子集,以求支持度,这样加入数据集很大的情况下,效率会降低。FP-growth效率比较好
- 但是apriori的算法扩展性较好,可以用于并行计算等领域。(没试过。。网上找的)
11. 使用FP-growth快速找到频繁集
- 总的来说,FP-growth只需要扫描数据集两次就能够找到频繁集。

发现频繁集的基本过程:
- 构建FP树
- 从FP树中挖掘频繁集
工作原理
首先构建FP树,然后利用它来挖掘频繁集。第一次扫描是统计元素出现的个数,对于那些小于最小支持度的项直接移除。第二次是扫描只考虑那些频繁项。
从一棵FP树中挖掘频繁项集
- 从FP树很火的条件模式基
- 利用条件模式基,构建条件FP树
- 迭代重复步骤1和步骤2,直到树包含一个元素项为止
12.利用PCA来简化数据
数据简化原因:
- 可视化
- 使得数据集更容易使用
- 降低很多算法的计算开销
- 去除噪声
- 使得结果易懂
降维的方法有:
- 主成分分析(PCA)
- 因子分析
- 独立成分分析(ICA)
PCA
伪代码:

- 找出数据差异度前N大的方向
- 差异度可以通过协方差矩阵和特征值来计算得到(协方差矩阵的特征值)
- 观察特征值,特征值为0的特征都是其他特征的副本,也就是说,它们可以通过其他特征来表示,本身并没有提供额外的信息,只是起到噪声的作用。
- 当一部分特征值的数量级与其余特征值数量级相差较大的时候,这意味着这部分就是重要特征。
那N怎么确定?
-
下图是一个例子的特征值示意图:
 可以看出前6个特征方差最大。因此我们观察就能得到pca的参数N,然后就可以简化数据得到低维度数据输入到分类器中。
可以看出前6个特征方差最大。因此我们观察就能得到pca的参数N,然后就可以简化数据得到低维度数据输入到分类器中。 - 降维技术往往备用做预处理操作,达到数据清洗的目的。
13.利用SVD简化数据

- SVD:singular values decomposition 奇异值分解
- 作用:去除噪声和冗余信息。利用了SVD,我们能用小得多的数据集表示原始数据集。
- SVD是矩阵分解的一种类型,矩阵分解就是将矩阵分解成若干个独立部分的过程。
- 矩阵往往只有一小部分是有用的其余得都是噪声。
- SVD 将矩阵分为三部分:
Data_{m \times n} = U_{m\times m}\cdot \Sigma_{m \times n} \cdot V^T_{n \times n}其中Σ矩阵是奇异矩阵(只在对角线有值),并且是从大到小排列。这些对角值称为奇异值。
- 其中有个普遍事实:当r个奇异值后奇异值都是0的话,说明数据集有r个是重要的特征,其余特征都是噪声或者冗余特征。
- 当你想拿去剩下k个特征的话你就那U的m*k Σ的k*n V的n*k 相乘就可以得到简化后的数据了
- python处理SVD很简单,numpy 的linalg包里面有 ```python import numpy as np
U, Sigma, VT = np.linalg.svd([[1, 1], [7, 7]])
- 其中Sigma以行向量的形式给出,因为除了对角其他都为0

#### 如何知道需要保留前几个奇异值呢?
- 一种办法是保留矩阵的90%信息,通过计算奇异值的平方和,直至加到了总平方和的90%
- 第二种方法是凭借经验去设定,比如说有1W个奇异值就拿前面2000-3000个。
#### 基于协同过滤的推荐系统
- 协同过滤(collaborative filtering):通过将用户和其他用户的数据进行对比来实验推荐的。
- 基于相似度的折中来推荐。包括物品之间的相似度和用户之间的相似度。
- 相似度的计算方法:
1. 基于欧氏距离
2. 皮尔逊相关系数 corrcoef
3. 余弦相似度,计算两个向量夹角的余弦值。如果夹角为90度,则相似度为0,如果两个向量的方向相同,则相似度为1.0.
```math
cos\theta = \frac{A \cdot B}{||A||||B||}
其中||||是二阶范数的意思,python中linalg.norm可以计算
利用SVD压缩图像
步骤很简单:
- 首先得将图片读入,PIL可以用 PIL.Image.open
- 然后读入矩阵数据,利用SVD分解,看到什么时候达到需要的信息量。
- 然后重新乘回去用matplotlib.pyplot.imshow(数组)即可显示
14. 大数据下MapReduce
- 工作流程:单个作业被分成很多小份,输入数据也被切片分发到每个节点,各个节点只在本地数据上做运算,对应的运算代码成为mapper,整个过程被称作map阶段。第二部的处理阶段被称为reduce阶段,对应运行代码成为reducer。reducer的输出就是程序的自重执行结果。
- 优势:程序可以以并行的方式执行。
- Note:在任何时候,每个mapper或reducer之间都不进行通信。每个节点只处理自己的事务,且在本地分配的数据集上运算。