一、循环序列模型
例:Harry Porter invented a new spell. 如何表示一个单词?
答: 建立一个词典(现在NLP任务10000词以上)。然后找到单词的位置,用独热编码表示。
- 遇到不在词典里的单词时,建立一个新的标(单词)记,例如unk来表示。
RNN
- 在每一个时刻,在计算当前时刻的输出值(当前时刻的y,和输出到下一时刻的activation value)都考虑到当前时刻以前的信息。输出只要加一层输出层(softmax、sigmoid等)即可得到当前时刻的输出值(predict)。
如下图所示:

前向传播计算方法:

特点
- 后面的单词可以用前面单词的信息。
- 缺点:仅仅时利用前面单词的信息是不够的。还需要利用后面的单词。
- 激活函数一般用tanh
RNNS的种类:

- language model的作用是评估一句话出现的可能性。
- RNNS也存在梯度消失/爆炸问题
如何解决长距离时刻之间的依赖问题?- GRU & LSTM
GRU

- GRU单元(门控循环单元): 更好地捕捉长距离的依赖。让RNN更加可靠。
- 与LSTM相比, 更简单,更容易构造更复杂的网络
- 只有两个门,计算更快捷
LSTM

- 三个门:更新门、遗忘门、输出门,因此比GRU更加灵活、更加powerful

双向RNN Bidirectional RNN
特点:
-兼顾过去和未来的信息
-
计算forward propogation时,在原来的基础上加了反向单元
- 虚线是反向的RNN
- 从上图可以看出,双向RNN的主题结构就是两个单向RNN的结合。在每一个时刻t,输入会同时提供给这两个方向相反的RNN,而输出则是由这两个单向RNN共同决定(可以拼接或者求和等)。
同样地,将双向RNN中的RNN替换成LSTM或者GRU结构,则组成了BiLSTM和BiGRU。
缺点:
- 需要完整序列
- 例如在语音系统中,我们要等一个人完整地说完整一句话才能做后续的操作。
deep RNN

- 将之前的结构垂直堆叠就构成了多层的RNN
- 训练需要很多计算资源
- 不会像CNN那样有很多的隐藏层
- 一般来讲3层就足够多了,因为时间序列通常很长,3层已经是很庞大的网络了。
二、 NLP 与 word embedding
ONE的缺点:
- 不能捕捉词之间的相关性
- 维度过大
word embedding

- 正如上图所示,现在单词不是仅仅用词典+独热编码的形式转换,而是用一个具有300维特征(语义)的向量表示,两个向量值越相似,说明这两个单词越具备同样的特性。
- 更抽象,更丰富,更好地表示一个词。
- visualization of data using t-SNE
word embedding与迁移学习
有了word embedding 我们就可以更好地迁移学习,步骤如下:
- 从大量的文本集合中学习word Embeddings(1-100B ),或者从下载别人的的word Embeddings模型;
- 将上步得到的模型用到我们的NLP任务上。
- (optional)使用我们的数据对word Embeddings模型进行细调。
判断两个向量的相似度函数:
- 余弦相似度函数(Cosine similarity):也就是向量 u 和 v 的内积
sim(u,v) = \dfrac{u^{T}v}{||u||_{2}||v||_{2}}
或者由以下来表示:
CosineSimilarity(u, v) = \frac {u . v} {||u||_2 ||v||_2} = cos(\theta)
- 欧氏距离:
||u-v||^{2}
嵌入矩阵
在我们要对一个词汇表学习词嵌入模型时,实质上就是要学习这个词汇表对应的一个嵌入矩阵 E 。当我们学习好了这样一个嵌入矩阵后,通过嵌入矩阵与对应词的one-hot向量相乘,则可得到该词汇的embedding,如下图所示:
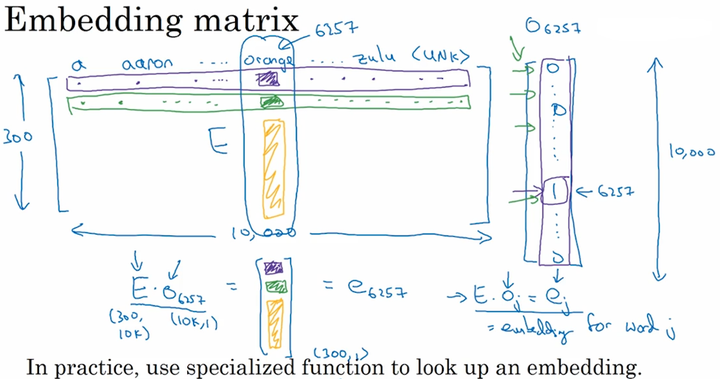
学习词嵌入
我们将要预测的单词称为目标词,其是通过一些上下文推导预测出来的。对于不同的问题,上下文的大小和长度以及选择的方法有所不同。
- 选取目标词之前的几个词;
- 选取目标词前后的几个词;
- 选取目标词前的一个词;
- 选取目标词附近的一个词,(一种Skip-Gram模型的思想)。
skip-gram
word2vec
Word2vec 的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。
语义情感分析
平均值模型
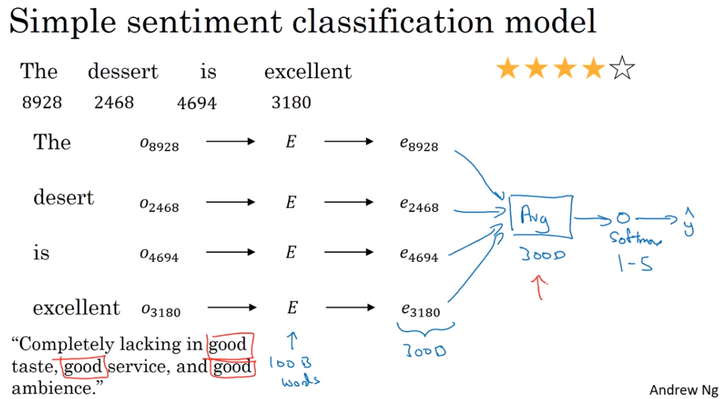 简单的语义情感将一句话里面的单词简单做平均,然后softmax出结果。
简单的语义情感将一句话里面的单词简单做平均,然后softmax出结果。
缺点:没有考虑到语序
因此用RNN来做情感分析应该是一个good idea
RNN情感分析模型:
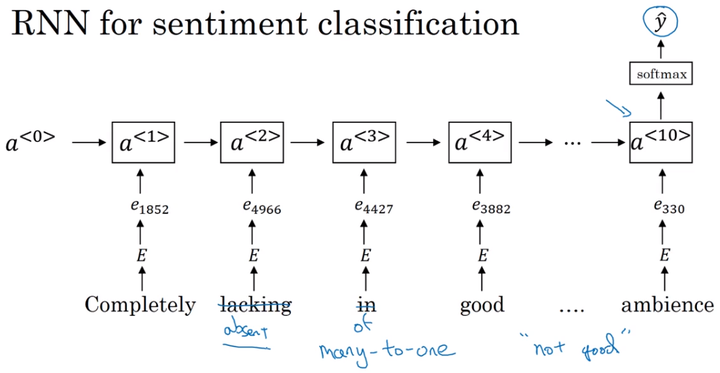
- 特点:多对一
处理偏见问题
目前的偏见问题:
以一些预料库中学习到的词嵌入向量,会发现学习到的词向量存在下面一些具有性别、种族等偏见,这反映了人们在历史的写作中存在的这种社会偏见。
例如,在英语中,只有一小部分单词是有偏的,例如,grandfather-grandmother,boy-girl。例如doctor这些词我们更希望其是中性的。
处理步骤:
- identify the bias direction:找出我们想要纠正的偏的趋势。例如性别
- Neutralize:中和。对于中性词做处理避免偏见。
- Equalize pairs:均衡步。如下所示,即将有偏的词语更加均衡化。使得类似与babysister相关的中性词对于actor和actress更加无偏。

Keras 与 mini-batch
跟其他的深度学习模型不一样的是,自然语言处理的数据集每个句子的长度是不一样的。那么训练起来就很困难。
padding就是专门来解决这个问题的。通过设定一个最大句子长度,剩余的位置补0即可。例如, 句子 “i love you” 可以被表示为 (ei,elove,eyou,0 ,0 ,…,⃗ )
三、seq2seq
以机器翻译为例:
- encode network + decode network
- encoding network 负责将输入的句子变成一个向量,decoding network负责将这个向量转化为输出
- 结构如下图所示:

该工作与另外一个根据图像生成文字的工作也很相似,如下图所示:
 将AlexNet的softmax输出层去掉,得到一个向量,然后输入到后面的decoding network
将AlexNet的softmax输出层去掉,得到一个向量,然后输入到后面的decoding network
Picking the most likely sentence
上面提到的解码网络,基于编码网络得到的输入向量,我们会得到一系列的概率分布。
P(y^{<1>},...,y^{<T_y>} | x)
假如按照之前language model那样按照概率分布随机选取单词的话,翻译结果的不确定性就大大增加,如果幸运的话得到结果不错,但是运气不好的话可能会生成很不好的结果。因此不能用sampling来产生结果,而是选择最好的最大可能性的句子:
argmax \ P(y^{<1>},...,y^{<T_y>} | x)
Beam search
预设Beam width = 3 (每一步都选概率最大的3个),当B=1时,即跟之前贪心算法一样(选概率最大的)
Beam search机制如下所示:
 重要公式:
重要公式:
P(y^{<1>}, y^{<2>}|x) = P(y^{<1>}|x)P(y^{<2>}|x, y^{<1>})
改善Beam search效果的两个措施
- 对概率加log函数,避免p过小(电脑浮点数无法表达)
- 不再求sum max,而是求均值。sum max的缺点是模型会偏向于短输出(因为是累加的,单词越少结果肯定越小)。在平时中我们会采用一个较为缓和的方法,那就是不是直接除以总单词数,而是引入一个α参数,如下图所示

- PS:α是一个可以调节的参数,当α=0的时候,即无normalization,α=1的时候即完全平均。
怎样选择B
B 越大 时间越久,需要内存越高
从1到3到10,效果提升快,从1000到3000,效果提升不显著。
不像DFS BFS,beam search 不能保证找到最优的结果。
区分RNN模型和beam search模型的误差
假如整体模型表现不好,我们需要发现到底是哪一步出现问题。

- case1:这种情况beam search应该选y*但是选了yhat,所以是beam search 出现了问题
- case2:反之,RNN模型出现问题。
BLEU 得分
因为自然语言处理的特殊性,机器翻译有可能很多个结果都是很不错的,这个时候应该如何评估呢?
注意力模型
让RNN集中注意在一小段输入中,即不同的单词对输出有不同的权重影响。
语音识别
预处理:先产生声谱图
以前语音识别语言学家认为要用基本的音位单元来表示一段语音,但是现在在端对端的模型里面不需要了。
end-to-end模型:输入是音频,输出是转换后的文字
- CTC:计算误差时将重复的字符折叠起来。“_”是一种特殊的字符,表示blank(空白,注意要与空格区分) 例如:“the quick brown fox” 输出:ttt_h_eee__ q…